Recently we added functionalities for users to subscribe to their sports of interest so we can send them more personalized content. Given the dynamic nature of sports / match / fixture , I wanted the subscription topics flexible but still hierarchical. The idea was to enable someone to get each and every notification that happens on cricket or to choose a particular team / player etc and get more granular notification.
After trying to model the hierarchy into a RDBMS & document DB , we quickly realized traditional DB is just a bad fit for such recursive model design and the data retrieval queries will be too expensive.
This is finally the big enough problem when you can sell / justify introducing a completely new tool to address the issue. And my chance to use graph-db in production. I was introduced to the graph db concept to a previous project of mine and was really impressed by the ease of natural domain model mapping into the DB via the graph concept.
After some basic R & D, we decided to go with Orientdb. Having used elasticsearch cluster products , Orientdb clustering model seemed more natural compared to neo4j. Having said that, having a graph on a distributed cluster is not a easy problem which we realized later the hard way.
We could easily map our model in a graph schema like the following:
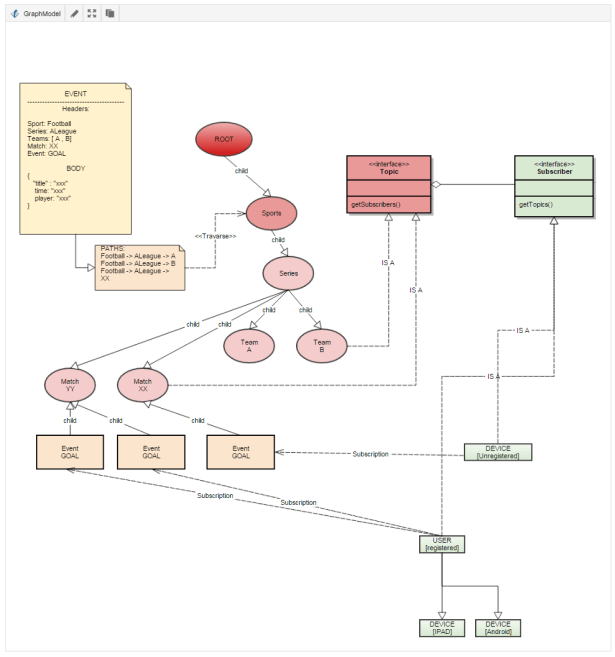
Notice how easily the concept of an unregistered device / user , and a user with multiple device fits into the domain. A user can subscribe to any node on the Tree that is Topic and the events automatically flows through the Subscriber.
This is how it looks like on Database:

Performance:
With the default setup & no special tuning, the system is looking up 10,000 device-id to push the notification in < 500 ms , which is quite good for us. however, the orientdb-support tells us that it can be made even faster.
Lessons Learned:
> We went with latest major production release 2.1 (which was released only 1 week ago) , and got burnt by many bugs / corner cases. It took upto 2.1.7 to finally have it stable.
> Use TinkerPop (think jdbc for database) apis so you can switch between orientdb / neo4j
> If coding in java, use Frames api to maintain the Domain mapping
> Frames api is not properly tuned. I had to re-write most of my queries in gremlin . I am not sure about neo4j but orientdb recommends using gremlin / sql to run the search queries.
> Partition your clusters appropriately, it will result in proper utilization of all nodes in your cluster.

